
OpenAI a récemment annoncé une avancée majeure dans le domaine de l’intelligence artificielle avec le lancement de la distillation de modèles disponible via son API, détaillée sur leur page officielle. Cette innovation permet aux développeurs et aux entreprises de créer des modèles d’IA plus légers et plus efficaces sans compromettre les performances.
En offrant la possibilité de distiller des modèles complexes en versions simplifiées, OpenAI ouvre la voie à une adoption plus large de l’IA dans divers secteurs, tout en réduisant les coûts et en améliorant la réactivité des applications.
Dans cet article, nous examinerons en profondeur cette annonce et comment mettre en oeuvre ces nouvelles possibilités.

Qu’est-ce que la distillation de modèles ?
La distillation de modèles est un processus où un modèle complexe et volumineux (le modèle enseignant) transfère ses connaissances à un modèle plus simple et plus petit (le modèle étudiant).
L’objectif est de maintenir une performance similaire tout en réduisant la taille et la complexité du modèle étudiant.
- Réduction de la Taille : Les modèles distillés sont moins gourmands en mémoire, ce qui facilite leur déploiement sur des appareils aux ressources limitées.
- Efficacité Computationnelle : Moins de puissance de calcul est nécessaire pour exécuter le modèle, ce qui réduit les coûts opérationnels.
- Maintien des Performances : Malgré leur taille réduite, les modèles distillés peuvent approcher, voire égaler, les performances des modèles enseignants.
Comment fonctionne la distillation de modèles
- Entraînement du Modèle Enseignant : Un modèle complexe est d’abord entraîné sur un vaste ensemble de données pour atteindre des performances optimales.
- Transfert des Connaissances : Les sorties du modèle enseignant sont utilisées comme guide pour entraîner le modèle étudiant.
- Optimisation : Le modèle étudiant est affiné pour reproduire le comportement du modèle enseignant avec une précision maximale.
L’Application de la distillation par OpenAI dans ses API
OpenAI utilise la distillation de modèles pour améliorer l’accessibilité et l’efficacité de ses API.
En distillant des modèles avancés comme GPT-4o, OpenAI peut offrir :
- Des Réponses Plus Rapides : Les modèles plus légers traitent les requêtes à une vitesse supérieure.
- Une Accessibilité Accrue : Les développeurs peuvent intégrer des modèles puissants sans nécessiter une infrastructure coûteuse.
- Une Meilleure Expérience Utilisateur : Les applications basées sur l’IA deviennent plus réactives et fluides.
Avantages clés pour les développeurs et les entreprises
- Économies de Coûts : Réduction des dépenses liées à l’hébergement et au calcul.
- Évolutivité : Possibilité de servir un plus grand nombre d’utilisateurs sans compromettre les performances.
- Flexibilité : Intégration facilitée dans divers environnements, y compris les appareils mobiles et les systèmes embarqués.
Implications pour l’industrie de l’IA
La distillation de modèles ouvre de nouvelles perspectives pour l’innovation en IA :
- Démocratisation de l’IA : Permet aux petites entreprises et aux startups d’accéder à des technologies auparavant réservées aux grands acteurs.
- Applications Diversifiées : Favorise le développement d’applications dans des domaines tels que la santé, l’éducation et les services financiers.
- Durabilité : Contribue à réduire l’empreinte carbone des technologies d’IA en diminuant la consommation énergétique.
Comment distiller un modèle en utilisant l’interface d’OpenAI ?
Objectifs du tutoriel
- Comprendre l’interface d’OpenAI pour le fine-tuning et la distillation des modèles
- Préparer les données d’entraînement et de validation pour le fine-tuning
- Configurer les hyperparamètres essentiels pour distiller efficacement un modèle
- Lancer le processus de fine-tuning et évaluer les résultats
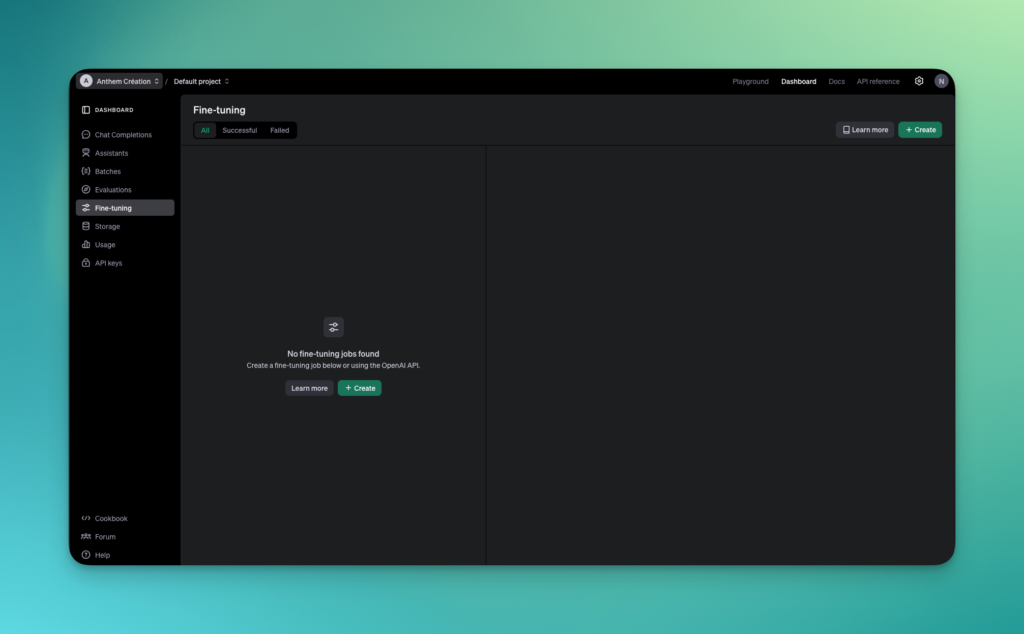
Étape 1 : Accéder à l’interface de fine-tuning
- Connectez-vous à OpenAI : Assurez-vous d’être connecté à votre compte sur OpenAI et d’avoir accès à l’API pour la création de modèles fine-tunés.
- Naviguez vers le Tableau de bord : Depuis votre tableau de bord, dans la barre de navigation à gauche, cliquez sur « Fine-tuning » comme illustré dans l’image.
- Créer un nouveau modèle : Cliquez sur le bouton vert « Create » pour ouvrir le formulaire de création d’un modèle fine-tuné.
Étape 2 : Sélectionner le modèle de base
Dans la première section du formulaire, vous devez choisir un modèle de base sur lequel appliquer la distillation. Voici comment procéder :
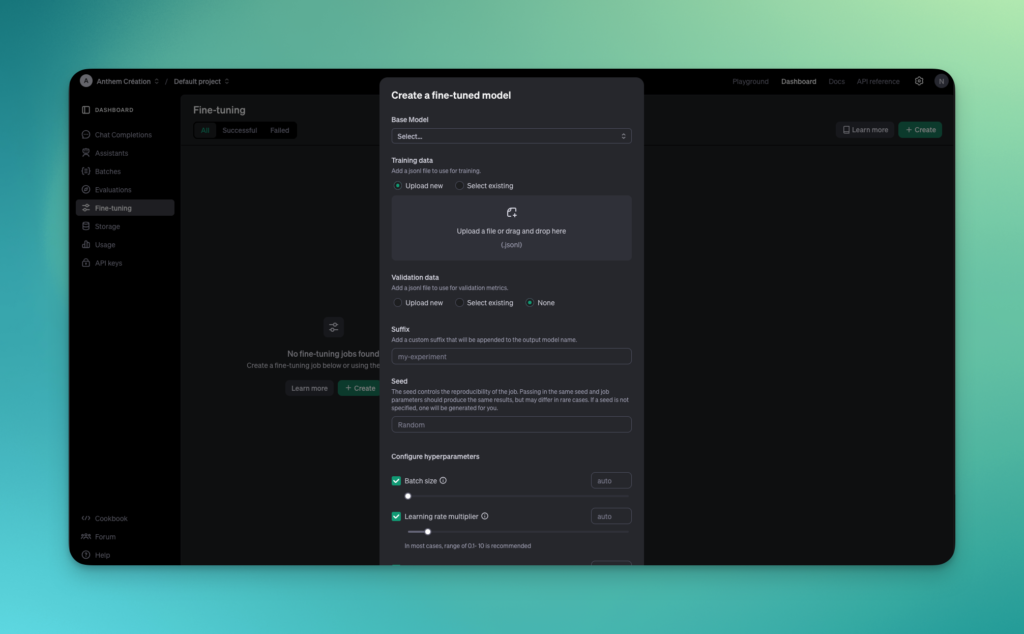
- Base Model : Cliquez sur le menu déroulant et choisissez le modèle que vous souhaitez distiller. Les options incluent des modèles populaires comme GPT-3 et GPT-4. Ces modèles complexes serviront de point de départ pour la distillation.
Étape 3 : Ajouter les données d’entraînement
La distillation de modèle nécessite des données d’entraînement pour guider l’optimisation du modèle.
- Training Data : Vous devez fournir un fichier au format
.jsonlcontenant les exemples que le modèle utilisera pour s’entraîner. Vous pouvez soit :
- Upload new : Importer un nouveau fichier de données en cliquant sur « Upload a file », ou
- Select existing : Sélectionner un fichier déjà disponible dans votre espace de stockage.
Le fichier .jsonl doit être structuré avec des paires de requêtes et réponses générées par le modèle enseignant pour guider le modèle étudiant.
- Validation Data (optionnel) : Vous pouvez également fournir un fichier de validation pour mesurer les performances du modèle pendant l’entraînement. Ce fichier doit également être au format
.jsonl.
Étape 4 : Configurer le nom du modèle et la reproductibilité
- Suffix : Ajoutez un suffixe à votre modèle pour le différencier des autres expérimentations. Par exemple, entrez « my-experiment » pour nommer votre modèle « gpt3-my-experiment ».
- Seed : La seed permet de reproduire le même résultat lors d’entraînements multiples. Vous pouvez définir une seed spécifique pour assurer une reproductibilité, ou laisser l’option « Random » si cela n’est pas nécessaire.
Étape 5 : Configurer les hyperparamètres
L’interface permet de régler plusieurs hyperparamètres essentiels pour la distillation du modèle :
- Batch Size : Activez l’option « Batch size » pour ajuster la taille des lots d’entraînement. La valeur par défaut est généralement optimale, mais vous pouvez ajuster cette taille selon la capacité de votre infrastructure.
- Learning Rate Multiplier : Le taux d’apprentissage détermine la vitesse à laquelle le modèle ajuste ses paramètres. Vous pouvez soit utiliser une valeur par défaut automatique, soit définir une valeur manuellement (généralement entre 0.01 et 10 pour la distillation).
Étape 6 : Lancer le processus de distillation
- Vérification des paramètres : Avant de lancer l’entraînement, vérifiez que tous les paramètres sont correctement configurés.
- Lancer le fine-tuning : Cliquez sur « Create » pour démarrer le processus de distillation. Vous verrez ensuite l’état de votre travail (en attente, en cours ou terminé) apparaître dans le tableau de bord.
Étape 7 : Suivi et évaluation du modèle distillé
Une fois que l’entraînement est terminé, vous pouvez évaluer les performances du modèle en utilisant l’API OpenAI.
- Évaluation des résultats : Après la distillation, accédez aux résultats et aux métriques d’évaluation (comme les pertes sur les données de validation). OpenAI fournit ces informations pour vous aider à ajuster vos futurs modèles.
- Test du modèle : Vous pouvez tester directement le modèle fine-tuné pour voir s’il atteint vos objectifs de performance et d’efficacité.
Astuces et bonnes pratiques
- Optimisez le jeu de données : Assurez-vous que les données d’entraînement fournies couvrent bien les cas d’utilisation spécifiques de votre modèle.
- Équilibrez les hyperparamètres : Ajustez les paramètres comme le taux d’apprentissage et la taille des lots pour trouver un compromis entre précision et vitesse de convergence.
- Itérations multiples : Testez plusieurs versions du modèle avec différentes seeds et paramètres pour voir ce qui fonctionne le mieux dans votre contexte.
Conclusion
La distillation de modèles via l’interface de fine-tuning d’OpenAI est un processus puissant et relativement simple grâce à l’UI intuitive du Playground.
En suivant ces étapes, vous pouvez réduire la taille de vos modèles tout en conservant leurs performances, ce qui les rend idéaux pour des applications à grande échelle ou dans des environnements contraints en ressources.
Pour plus de détails, vous pouvez consulter la documentation officielle d’OpenAI ou rejoindre la communauté pour obtenir des conseils supplémentaires et partager vos résultats.
Articles Similaires

WordPress, Headless ou IA sur mesure : quel CMS choisir en 2026 ?
Pendant 20 ans, la réponse était simple : WordPress. En 2026, le paysage a radicalement changé. Headless CMS, backends IA sur mesure, agents autonomes… Ce guide vous aide à faire…

Genie 3 : Le World Model qui génère des environnements 3D interactifs
Google DeepMind vient de frapper un grand coup avec Genie 3, son nouveau world model génératif. Oubliez les vidéos passives générées par l’IA : ici, on parle de mondes 3D…