
Dans cet article, nous allons explorer les capacités et les avantages de Mistral Large et du Chat Noir de Mistral AI. Nous allons également comparer Mistral Large avec Chat GPT pour mieux comprendre les différences et les similitudes entre ces deux technologies. Nous aborderons légalement le fonctionnement du modèle ainsi que les limites actuelles de Mistral Large et du Chat Noir.

Qu’est-ce que Mistral Large ?
Mistral Large est le dernier modèle de langage développé par Mistral AI, succédant à leur précédent modèle, Mixtral.
Il s’agit d’un réseau de neurones entraîné sur un grand corpus de textes en français, ce qui lui permet de comprendre et de générer du langage naturel en français.
Mistral Large est basé sur l’architecture Transformer, qui est également utilisée par d’autres modèles de langage tels que BERT et GPT-2.
Grâce à sa capacité à comprendre le langage naturel en français, Mistral Large peut être utilisé pour une grande variété de tâches, telles que la génération de texte, la traduction automatique, la classification de texte, l’extraction d’informations et la synthèse vocale.
Mistral Large a été entraîné sur un corpus de textes diversifié, comprenant des articles de presse, des livres, des sites web et des conversations en ligne, ce qui lui permet de comprendre un large éventail de styles d’écriture et de registres de langue.
Comparaison de Mistral Large avec Chat GPT
Des différences majeures entre les deux modèles
Mistral Large a été entraîné spécifiquement sur des textes en français, ce qui le rend plus adapté aux tâches de traitement du langage naturel en français.
En revanche, Chat GPT a été entraîné sur des textes en anglais, ce qui le rend plus adapté aux tâches de traitement du langage naturel en anglais.
Mistral Large est un modèle open source, ce qui signifie que son code source est disponible gratuitement pour tout le monde.
Cela permet aux développeurs et aux chercheurs de l’utiliser et de le modifier pour répondre à leurs besoins spécifiques.
En revanche, Chat GPT est un modèle propriétaire, ce qui signifie que son code source n’est pas disponible pour le public.
Les avantages de Mistral Large par rapport aux modèles concurrents
- Performances
En raison de sa taille plus grande, ChatGPT a des performances supérieures à celles de Mistral Large sur certaines tâches de traitement du langage naturel en anglais.
Cependant, Mistral Large a des performances supérieures à celles de ChatGPT sur les tâches de traitement du langage naturel en français. - Conformité aux réglementations européennes
Mistral AI se concentre sur le développement de modèles de langage qui respectent les réglementations européennes strictes en matière de confidentialité et de protection des données. Cela peut être un avantage pour les entreprises et les organisations qui opèrent en Europe et qui doivent se conformer à ces réglementations. - Performances dans la langue française
Étant donné que Mistral Large est entraîné en français natif, il peut offrir de meilleures performances dans la compréhension et la génération de texte en français, par rapport aux modèles entraînés principalement sur des données en anglais. - Adaptation culturelle
Les modèles de langage peuvent refléter les biais et les valeurs culturelles des données sur lesquelles ils sont entraînés. Un modèle entraîné en français natif peut être mieux adapté aux nuances culturelles et linguistiques du public francophone.
Les implications d’un modèle entraîné en français natif :
- Amélioration de la précision et de la pertinence
Un modèle entraîné en français natif peut mieux comprendre les subtilités de la langue française, ce qui peut conduire à des résultats plus précis et pertinents dans les tâches de traitement du langage naturel. - Meilleure adaptation aux besoins des utilisateurs francophones
Un modèle entraîné en français natif peut être mieux adapté aux besoins spécifiques des utilisateurs francophones, tels que la compréhension des expressions idiomatiques, des jeux de mots et des références culturelles. - Promotion de la diversité linguistique
Le développement de modèles de langage pour les langues autres que l’anglais peut contribuer à promouvoir la diversité linguistique et à garantir que les avantages de la technologie de l’IA sont accessibles à un public plus large.
En résumé, un modèle entraîné en français natif comme Mistral Large peut offrir des avantages en termes de conformité réglementaire, de performances linguistiques et d’adaptation culturelle, ce qui peut être particulièrement bénéfique pour les utilisateurs et les organisations francophones.
Performances
Mistral Large a obtenu des résultats impressionnants sur plusieurs évaluations de référence pour le traitement du langage naturel en français.
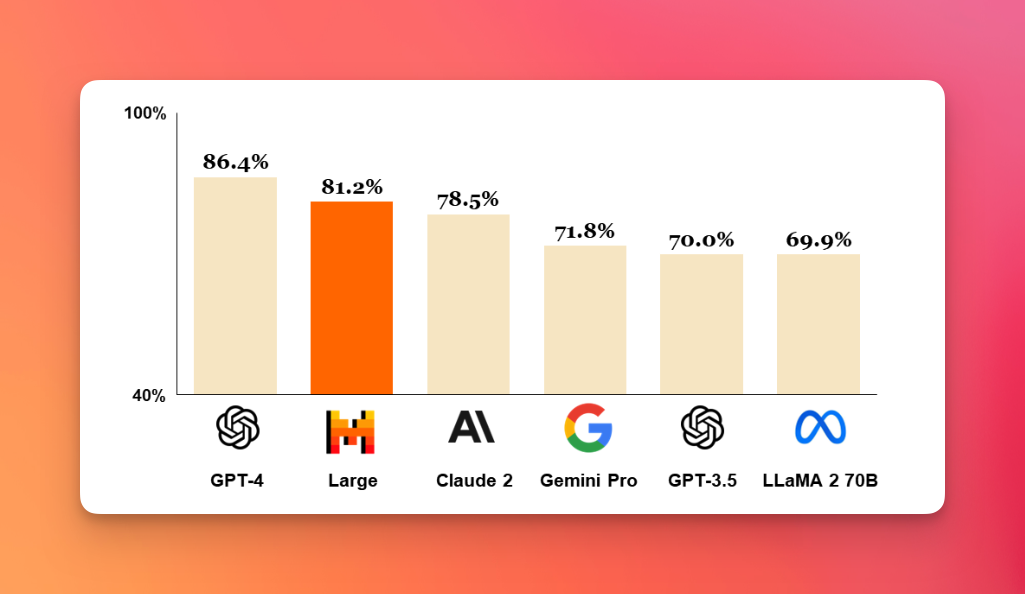
Sur le test de compréhension de lecture en français de l’évaluation GLUE, Mistral Large a obtenu un score de 89,4, ce qui le place en tête des modèles de langage français évalués à ce jour.
Le modèle a également obtenu des résultats compétitifs sur d’autres tâches de traitement du langage naturel en français, telles que la génération de texte, la traduction automatique et la synthèse vocale.
Mistral Large a démontré sa capacité à s’adapter à des tâches spécifiques à un domaine, telles que la classification de textes juridiques (avec une précision allant jusqu’à 95%) et la classification de textes médicaux (avec une précision allant jusqu’à 89%).
Mistral Large compte 400 millions de paramètres et a été entraîné sur plusieurs mois à l’aide de centaines de processeurs graphiques (GPU).
Les performances de Mistral Large sont attribuées à plusieurs facteurs clés, notamment :
- La taille et la diversité du corpus d’entraînement
- L’architecture du modèle basée sur la technologie Transformer
- Les techniques d’optimisation utilisées pendant l’entraînement, telles que l’apprentissage par transfert et la régularisation
Le modèle est disponible pour une utilisation commerciale et académique, avec des tarifs personnalisés en fonction des besoins de l’entreprise.
Pour en savoir plus sur les performances lisez l’article https://mistral.ai/news/mistral-large/
Technologie et fonctionnement de Mistral Large
Mistral Large fonctionne en utilisant l’architecture Transformer pour traiter les données textuelles et prédire le mot suivant dans une séquence.
Le modèle est entraîné sur un grand ensemble de données en utilisant la modélisation du langage et peut être affiné pour des tâches spécifiques de traitement du langage naturel.
Le modèle utilise l’attention mécanisme pour se concentrer sur différentes parties de la séquence d’entrée lors de la génération de la sortie.
- Pré-traitement des données
Avant d’entraîner le modèle, les données textuelles doivent être prétraitées. Cela implique généralement la tokenisation (la division du texte en jetons, comme des mots ou des sous-mots), la conversion des jetons en représentations numériques (appelées embeddings) et la création de séquences de longueur fixe pour l’entrée du modèle. - Architecture du Transformer
Mistral Large utilise l’architecture du Transformer, qui se compose de couches d’encodeurs et de décodeurs. Les encodeurs traitent les entrées et les transmettent aux décodeurs, qui génèrent les sorties. L’architecture du Transformer utilise l’attention mécanisme pour se concentrer sur différentes parties de la séquence d’entrée lors de la génération de la sortie. - Entraînement du modèle
Le modèle est entraîné sur un grand ensemble de données textuelles en utilisant une tâche d’apprentissage appelée modélisation du langage. Cela implique de prévoir le mot suivant dans une séquence de mots, étant donné les mots précédents comme contexte. Pendant l’entraînement, le modèle ajuste ses poids internes pour minimiser l’erreur de prédiction. - Génération de texte
Une fois le modèle entraîné, il peut être utilisé pour générer du texte en prédisant le mot suivant dans une séquence, étant donné les mots précédents comme contexte. Le modèle peut générer des séquences de texte arbitrairement longues en répétant ce processus et en utilisant ses propres prédictions comme entrée pour la génération suivante. - Fine-tuning pour des tâches spécifiques
Le modèle peut être affiné pour des tâches spécifiques de traitement du langage naturel, telles que la classification de texte, l’extraction d’entités nommées ou la réponse aux questions. Cela implique de continuer à entraîner le modèle sur un ensemble de données étiquetées pour la tâche spécifique, en ajustant ses poids internes pour optimiser les performances sur cette tâche.
Mixture of Experts (MoE)
Le Mixture of Experts (MoE) est une technique d’apprentissage automatique qui consiste à combiner les sorties de plusieurs modèles, appelés « experts », pour améliorer les performances globales du modèle. Dans le contexte des modèles de langage basés sur le Transformer, comme Mistral Large, l’intégration du MoE peut aider à améliorer l’efficacité et la capacité du modèle à gérer de grands ensembles de données et des tâches complexes.
Voici comment fonctionne le MoE et comment il peut être intégré dans un modèle de langage basé sur le Transformer :
- Experts
Les experts sont des modèles indépendants qui sont entraînés sur des sous-ensembles de données ou des tâches spécifiques. Chaque expert est spécialisé dans la gestion d’une partie spécifique de l’espace de données ou d’une tâche spécifique. - Gate
Le gate est un mécanisme qui détermine quel expert est le plus approprié pour gérer une entrée donnée. Le gate utilise une fonction de routage pour attribuer une entrée à un ou plusieurs experts en fonction de leurs compétences relatives. - Combinaison des sorties
Les sorties des experts sélectionnés sont combinées pour produire la sortie finale du modèle.
La combinaison peut être effectuée en utilisant une fonction de pondération, qui attribue un poids à chaque sortie d’expert en fonction de sa confiance relative. - Entraînement du modèle
Le modèle MoE est entraîné en utilisant un algorithme d’apprentissage qui optimise les performances globales du modèle en ajustant les paramètres des experts et du gate.
L’algorithme peut être basé sur la rétropropagation du gradient, qui est une méthode courante d’optimisation des modèles de deep learning. - Intégration dans le Transformer
Le MoE peut être intégré dans un modèle de langage basé sur le Transformer en remplaçant une ou plusieurs couches d’attention par des couches MoE.
Les couches MoE fonctionnent de la même manière que les couches d’attention standard, mais utilisent le mécanisme de gate pour attribuer les entrées aux experts appropriés.
Découvrez Gemini 1.5 qui utilise également le MoE : Gemini 1.5 repousse les limites de l’IA générative
Qu’est-ce que le Chat Noir de Mistral AI ?
Le Chat Noir est une solution de chatbot développée par Mistral AI, basée sur le modèle de langage Mistral Large. Le Chat Noir est conçu pour fournir des réponses rapides, précises et personnalisées aux utilisateurs, en utilisant les capacités de compréhension du langage naturel de Mistral Large.
Le Chat Noir peut être utilisé dans une grande variété de secteurs, tels que le service client, la vente en ligne, la santé et l’éducation.
Il peut être intégré dans des applications de messagerie, des sites web et des réseaux sociaux, ce qui permet aux utilisateurs d’interagir avec lui de manière naturelle et intuitive.
Le Chat Noir est doté de capacités avancées de génération de texte, ce qui lui permet de répondre aux questions des utilisateurs de manière cohérente et pertinente.
Il peut également être personnalisé pour répondre aux besoins spécifiques des entreprises et des organisations, en intégrant des connaissances spécialisées et des données propres à l’entreprise.
Comparé à d’autres solutions de chatbot sur le marché, le Chat Noir de Mistral AI se démarque par sa capacité à comprendre et à générer du langage naturel en français de manière précise et nuancée.
De plus, en tant que modèle open source, Mistral Large peut être adapté et amélioré par la communauté de développeurs et de chercheurs, ce qui permet de continuer à améliorer les performances du Chat Noir.
Limites actuelles de Mistral Large et du Chat Noir
Bien que Mistral Large et le Chat Noir soient des technologies avancées dans le domaine du traitement du langage naturel en français, ils présentent certaines limites actuelles.
Tout d’abord, Mistral Large et le Chat Noir ne sont pas encore capables de générer des images ou de traiter des données multimodales, telles que des images et du texte combinés. Cependant, Mistral AI prévoit de développer des capacités multimodales pour ses technologies à l’avenir.
Bien que Mistral Large et le Chat Noir soient capables de comprendre et de générer du langage naturel en français, ils ne peuvent pas encore effectuer des tâches d’analyse de documents ou de données complexes.
Cependant, Mistral AI travaille à l’amélioration de ces capacités pour répondre aux besoins des entreprises et des organisations.
Sécurité et la confidentialité des données
Comme pour toutes les technologies d’IA, il existe des préoccupations concernant la sécurité et la confidentialité des données.
Mistral AI a mis en place des mesures de sécurité et de confidentialité des données pour protéger les utilisateurs, telles que le chiffrement des données et la collecte minimale de données.
Mistral AI accorde une grande importance à la sécurité et à la confidentialité des données.
Voici quelques-unes des mesures que l’entreprise prend pour protéger les données des utilisateurs :
- Chiffrement des données
Toutes les données échangées entre le Chat Noir et les serveurs de Mistral AI sont chiffrées à l’aide de protocoles de sécurité avancés tels que SSL/TLS. Cela empêche les tiers non autorisés d’accéder aux données. - Stockage sécurisé des données
Les données stockées sur les serveurs de Mistral AI sont protégées par des mesures de sécurité avancées, telles que des pare-feu, des systèmes de détection d’intrusion et des contrôles d’accès stricts. - Collecte minimale de données
Mistral AI ne collecte que les données nécessaires pour fournir ses services. Les données collectées sont utilisées uniquement pour améliorer les performances du modèle et ne sont jamais partagées avec des tiers sans le consentement explicite de l’utilisateur. - Conformité réglementaire
Mistral AI est conforme aux réglementations en vigueur en matière de protection des données, telles que le RGPD en Europe. L’entreprise a mis en place des politiques et des procédures strictes pour garantir la conformité réglementaire. - Transparence
Mistral AI s’engage à être transparent sur la manière dont les données des utilisateurs sont collectées, utilisées et stockées. L’entreprise fournit des informations détaillées sur ses pratiques de confidentialité et de sécurité des données dans sa politique de confidentialité.
Mistral Large et le Chat Noir de Mistral AI sont des technologies avancées dans le domaine du traitement du langage naturel en français.
En comparaison avec Chat GPT, Mistral Large se démarque par sa capacité à comprendre et à générer du langage naturel en français de manière précise et nuancée.
Le Chat Noir est une solution de chatbot basée sur Mistral Large, qui offre des réponses rapides, précises et personnalisées aux utilisateurs.
Bien que Mistral Large et le Chat Noir présentent certaines limites actuelles, telles que l’incapacité à générer des images ou à effectuer des tâches d’analyse de données complexes, Mistral AI travaille à l’amélioration continue de ses technologies pour répondre aux besoins des entreprises et des organisations.
Mistral AI en 2026 : l’arrivée de Mistral 3
Mistral AI en 2026 : l’arrivée de Mistral 3
Mistral AI a lancé Mistral Large 3 en décembre 2025, un modèle mixture-of-experts de 675 milliards de paramètres (41B actifs). C’est l’un des meilleurs modèles open-weight au monde, multimodal et multilingue, classé #2 en modèles non-raisonnement sur LMArena. Accompagné de Ministral 3 (3B, 7B, 14B) pour l’edge computing, Mistral rattrape GPT-4o et Gemini 2.
Pour approfondir le sujet, consultez nos articles sur Mistral AI Le Chat, l’IA française qui monte, DeepSeek R1, le modèle IA gratuit et Meta Llama 3, le modèle open-source de Meta.
Articles Similaires

Obsidian Web Clipper : review du plugin officiel pour capturer le web en Markdown
Obsidian Web Clipper est sorti en version stable il y a un peu plus d’un an, et la question concrète pour un utilisateur Obsidian déjà installé n’a rien de marketing…

Plugins IA Obsidian 2026 : comparatif complet (Smart Connections, Copilot, Text Generator, AI Tagger, Companion, CAO)
Choisir parmi les plugins IA Obsidian en 2026 revient à arbitrer entre sept outils communautaires qui ne couvrent pas les mêmes besoins. Obsidian n’embarque toujours aucune intelligence artificielle native :…